Improving the quality of training samples

Selecting good training samples for machine learning classification of satellite images is critical to achieving accurate results. Experience with machine learning methods has shown that the number and quality of training samples are crucial factors in obtaining accurate results [31]. Large and accurate datasets are preferable, regardless of the algorithm used, while noisy training samples can negatively impact classification performance [32]. Thus, it is beneficial to use pre-processing methods to improve the quality of samples and eliminate those that may have been incorrectly labeled or possess low discriminatory power.
It is necessary to distinguish between wrongly labeled samples and differences resulting from the natural variability of class signatures. When working in a large geographic region, the variability of vegetation phenology leads to different patterns being assigned to the same label. A related issue is the limitation of crisp boundaries to describe the natural world. Class definitions use idealized descriptions (e.g., “a savanna woodland has tree cover of 50% to 90% ranging from 8 to 15 m in height”). Class boundaries are fuzzy and sometimes overlap, making it hard to distinguish between them. To improve sample quality, sits provides methods for evaluating the training data.
Given a set of training samples, experts should first cross-validate the training set to assess their inherent prediction error. The results show whether the data is internally consistent. Since cross-validation does not predict actual model performance, this chapter provides additional tools for improving the quality of training sets. More detailed information is available on Chapter Validation and accuracy measurements.
Datasets used in this chapter
The examples of this chapter use two datasets:
cerrado_2classes: a set of time series for the Cerrado region of Brazil, the second largest biome in South America with an area of more than 2 million km^2. The data contains 746 samples divided into 2 classes (CerradoandPasture). Each time series covers 12 months (23 data points) from MOD13Q1 product, and has 2 bands (EVI, and NDVI).samples_cerrado_mod13q1: a set of time series from the Cerrado region of Brazil. The data ranges from 2000 to 2017 and includes 50,160 samples divided into 12 classes (Dense_Woodland,Dunes,Fallow_Cotton,Millet_Cotton,Pasture,Rocky_Savanna,Savanna,Savanna_Parkland,Silviculture,Soy_Corn,Soy_Cotton, andSoy_Fallow). Each time series covers 12 months (23 data points) from MOD13Q1 product, and has 4 bands (EVI, NDVI, MIR, and NIR). We use bands NDVI and EVI for faster processing.
library(sits)
library(sitsdata)
# Take only the NDVI and EVI bands
samples_cerrado_mod13q1_2bands <- sits_select(
data = samples_cerrado_mod13q1,
bands = c("NDVI", "EVI")
)
# Show the summary of the samples
summary(samples_cerrado_mod13q1_2bands)#> # A tibble: 12 × 3
#> label count prop
#> <chr> <int> <dbl>
#> 1 Dense_Woodland 9966 0.199
#> 2 Dunes 550 0.0110
#> 3 Fallow_Cotton 630 0.0126
#> 4 Millet_Cotton 316 0.00630
#> 5 Pasture 7206 0.144
#> 6 Rocky_Savanna 8005 0.160
#> 7 Savanna 9172 0.183
#> 8 Savanna_Parkland 2699 0.0538
#> 9 Silviculture 423 0.00843
#> 10 Soy_Corn 4971 0.0991
#> 11 Soy_Cotton 4124 0.0822
#> 12 Soy_Fallow 2098 0.0418Cross-validation of training sets
Cross-validation is a technique to estimate the inherent prediction error of a model [33]. Since cross-validation uses only the training samples, its results are not accuracy measures unless the samples have been carefully collected to represent the diversity of possible occurrences of classes in the study area [34]. In practice, when working in large areas, it is hard to obtain random stratified samples which cover the different variations in land classes associated with the ecosystems of the study area. Thus, cross-validation should be taken as a measure of model performance on the training data and not an estimate of overall map accuracy.
Cross-validation uses part of the available samples to fit the classification model and a different part to test it. The k-fold validation method splits the data into \(k\) partitions with approximately the same size and proceeds by fitting the model and testing it \(k\) times. At each step, we take one distinct partition for the test and the remaining \({k-1}\) for training the model and calculate its prediction error for classifying the test partition. A simple average gives us an estimation of the expected prediction error. The recommended choices of \(k\) are \(5\) or \(10\) [33].
sits_kfold_validate() supports k-fold validation in sits. The result is the confusion matrix and the accuracy statistics (overall and by class). In the examples below, we use multiprocessing to speed up the results. The parameters of sits_kfold_validate are:
-
samples: training samples organized as a time series tibble; -
folds: number of folds, or how many times to split the data (default = 5); -
ml_method: ML/DL method to be used for the validation (default = random forest); -
multicores: number of cores to be used for parallel processing (default = 2).
Below we show an example of cross-validation on the samples_cerrado_mod13q1 dataset.
rfor_validate <- sits_kfold_validate(
samples = samples_cerrado_mod13q1_2bands,
folds = 5,
ml_method = sits_rfor(),
multicores = 5
)
rfor_validate#> Confusion Matrix and Statistics
#>
#> Reference
#> Prediction Pasture Dense_Woodland Rocky_Savanna Savanna_Parkland
#> Pasture 6618 23 9 5
#> Dense_Woodland 496 9674 604 0
#> Rocky_Savanna 8 62 7309 27
#> Savanna_Parkland 4 0 50 2641
#> Savanna 56 200 33 26
#> Dunes 0 0 0 0
#> Soy_Corn 9 0 0 0
#> Soy_Cotton 1 0 0 0
#> Soy_Fallow 11 0 0 0
#> Fallow_Cotton 3 0 0 0
#> Silviculture 0 7 0 0
#> Millet_Cotton 0 0 0 0
#> Reference
#> Prediction Savanna Dunes Soy_Corn Soy_Cotton Soy_Fallow Fallow_Cotton
#> Pasture 114 0 36 12 25 41
#> Dense_Woodland 138 0 3 2 1 0
#> Rocky_Savanna 9 0 0 0 0 0
#> Savanna_Parkland 15 0 1 0 1 1
#> Savanna 8896 0 9 0 1 0
#> Dunes 0 550 0 0 0 0
#> Soy_Corn 0 0 4851 58 355 8
#> Soy_Cotton 0 0 40 4041 0 19
#> Soy_Fallow 0 0 29 0 1710 1
#> Fallow_Cotton 0 0 2 3 5 555
#> Silviculture 0 0 0 0 0 0
#> Millet_Cotton 0 0 0 8 0 5
#> Reference
#> Prediction Silviculture Millet_Cotton
#> Pasture 1 1
#> Dense_Woodland 102 0
#> Rocky_Savanna 0 0
#> Savanna_Parkland 0 0
#> Savanna 8 0
#> Dunes 0 0
#> Soy_Corn 0 3
#> Soy_Cotton 0 21
#> Soy_Fallow 0 0
#> Fallow_Cotton 0 20
#> Silviculture 312 0
#> Millet_Cotton 0 271
#>
#> Overall Statistics
#>
#> Accuracy : 0.9455
#> 95% CI : (0.9435, 0.9475)
#>
#> Kappa : 0.9365
#>
#> Statistics by Class:
#>
#> Class: Pasture Class: Dense_Woodland
#> Prod Acc (Sensitivity) 0.9184 0.9707
#> Specificity 0.9938 0.9665
#> User Acc (Pos Pred Value) 0.9612 0.8779
#> Neg Pred Value 0.9864 0.9925
#> F1 score 0.9393 0.9219
#> Class: Rocky_Savanna Class: Savanna_Parkland
#> Prod Acc (Sensitivity) 0.9131 0.9785
#> Specificity 0.9975 0.9985
#> User Acc (Pos Pred Value) 0.9857 0.9735
#> Neg Pred Value 0.9837 0.9988
#> F1 score 0.9480 0.9760
#> Class: Savanna Class: Dunes Class: Soy_Corn
#> Prod Acc (Sensitivity) 0.9699 1 0.9759
#> Specificity 0.9919 1 0.9904
#> User Acc (Pos Pred Value) 0.9639 1 0.9181
#> Neg Pred Value 0.9933 1 0.9973
#> F1 score 0.9669 1 0.9461
#> Class: Soy_Cotton Class: Soy_Fallow
#> Prod Acc (Sensitivity) 0.9799 0.8151
#> Specificity 0.9982 0.9991
#> User Acc (Pos Pred Value) 0.9803 0.9766
#> Neg Pred Value 0.9982 0.9920
#> F1 score 0.9801 0.8885
#> Class: Fallow_Cotton Class: Silviculture
#> Prod Acc (Sensitivity) 0.8810 0.7376
#> Specificity 0.9993 0.9999
#> User Acc (Pos Pred Value) 0.9439 0.9781
#> Neg Pred Value 0.9985 0.9978
#> F1 score 0.9113 0.8410
#> Class: Millet_Cotton
#> Prod Acc (Sensitivity) 0.8576
#> Specificity 0.9997
#> User Acc (Pos Pred Value) 0.9542
#> Neg Pred Value 0.9991
#> F1 score 0.9033The results show a good validation, reaching 94% accuracy. However, this accuracy does not guarantee a good classification result. It only shows if the training data is internally consistent. In what follows, we present additional methods for improving sample quality.
Cross-validation measures how well the model fits the training data. Using these results to measure classification accuracy is only valid if the training data is a good sample of the entire dataset. Training data is subject to various sources of bias. In land classification, some classes are much more frequent than others, so the training dataset will be imbalanced. Regional differences in soil and climate conditions for large areas will lead the same classes to have different spectral responses. Field analysts may be restricted to places they have access (e.g., along roads) when collecting samples. An additional problem is mixed pixels. Expert interpreters select samples that stand out in fieldwork or reference images. Border pixels are unlikely to be chosen as part of the training data. For all these reasons, cross-validation results do not measure classification accuracy for the entire dataset.
Hierarchical clustering for sample quality control
The package provides two clustering methods to assess sample quality: Agglomerative Hierarchical Clustering (AHC) and Self-organizing Maps (SOM). These methods have different computational complexities. AHC has a computational complexity of \(\mathcal{O}(n^2)\), given the number of time series \(n\), whereas SOM complexity is linear. For large data, AHC requires substantial memory and running time; in these cases, SOM is recommended. This section describes how to run AHC in sits. The SOM-based technique is presented in the next section.
AHC computes the dissimilarity between any two elements from a dataset. Depending on the distance functions and linkage criteria, the algorithm decides which two clusters are merged at each iteration. This approach is helpful for exploring samples due to its visualization power and ease of use [35]. In sits, AHC is implemented using sits_cluster_dendro().
# Take a set of patterns for 2 classes
# Create a dendrogram, plot, and get the optimal cluster based on ARI index
clusters <- sits_cluster_dendro(
samples = cerrado_2classes,
bands = c("NDVI", "EVI"),
dist_method = "dtw_basic",
linkage = "ward.D2"
)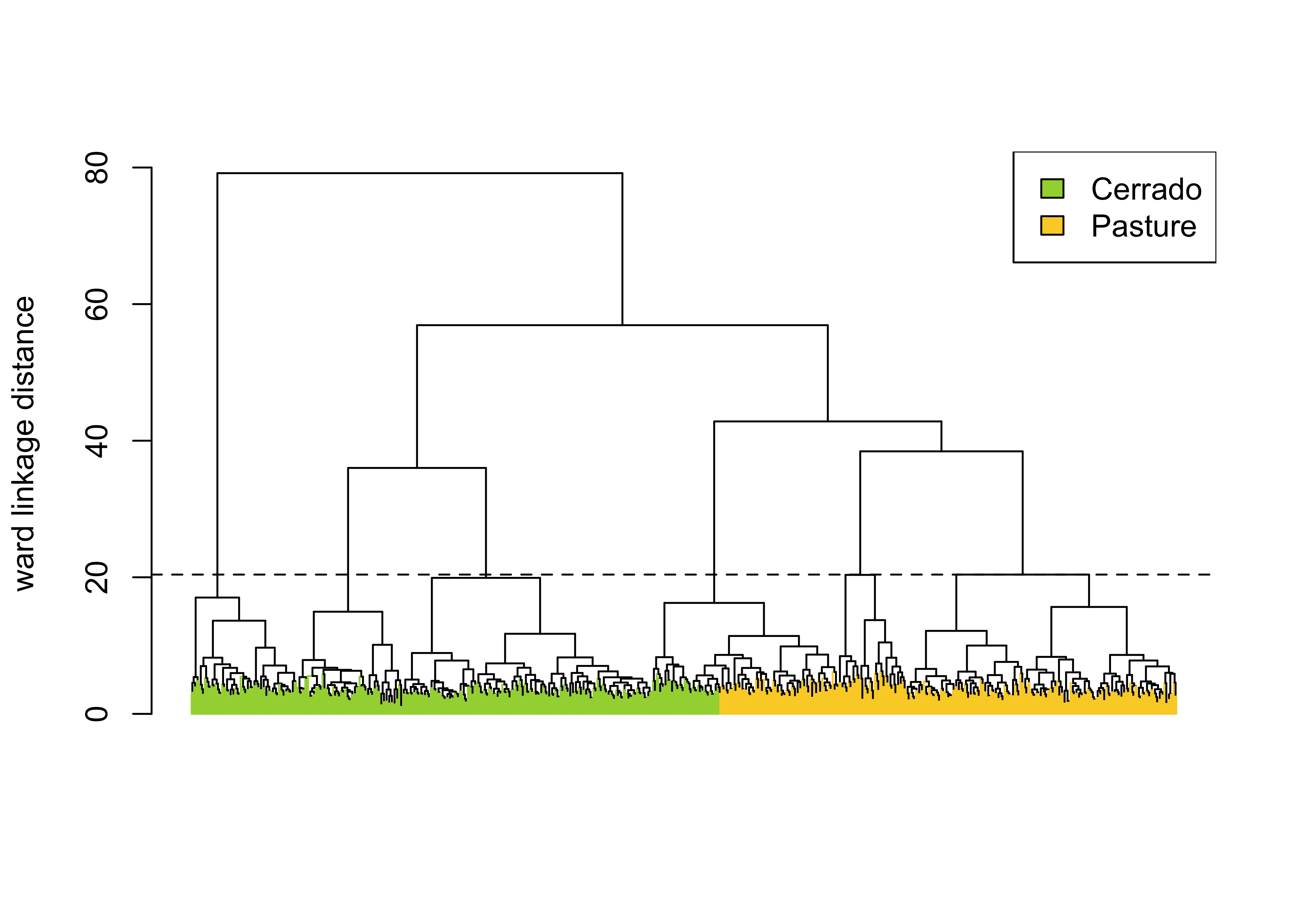
Figure 55: Example of hierarchical clustering for a two class set of time series (source: authors).
The sits_cluster_dendro() function has one mandatory parameter (samples), with the samples to be evaluated. Optional parameters include bands, dist_method, and linkage. The dist_method parameter specifies how to calculate the distance between two time series. We recommend a metric that uses dynamic time warping (DTW) [36], as DTW is a reliable method for measuring differences between satellite image time series [37]. The options available in sits are based on those provided by package dtwclust, which include dtw_basic, dtw_lb, and dtw2. Please check ?dtwclust::tsclust for more information on DTW distances.
The linkage parameter defines the distance metric between clusters. The recommended linkage criteria are: complete or ward.D2. Complete linkage prioritizes the within-cluster dissimilarities, producing clusters with shorter distance samples, but results are sensitive to outliers. As an alternative, Ward proposes to use the sum-of-squares error to minimize data variance [38]; his method is available as ward.D2 option to the linkage parameter. To cut the dendrogram, the sits_cluster_dendro() function computes the adjusted rand index (ARI) [39], returning the height where the cut of the dendrogram maximizes the index. In the example, the ARI index indicates that there are six clusters. The result of sits_cluster_dendro() is a time series tibble with one additional column called “cluster”. The function sits_cluster_frequency() provides information on the composition of each cluster.
# Show clusters samples frequency
sits_cluster_frequency(clusters)#>
#> 1 2 3 4 5 6 Total
#> Cerrado 203 13 23 80 1 80 400
#> Pasture 2 176 28 0 140 0 346
#> Total 205 189 51 80 141 80 746The cluster frequency table shows that each cluster has a predominance of either Cerrado or Pasture labels, except for cluster 3, which has a mix of samples from both labels. Such confusion may have resulted from incorrect labeling, inadequacy of selected bands and spatial resolution, or even a natural confusion due to the variability of the land classes. To remove cluster 3, use dplyr::filter(). The resulting clusters still contain mixed labels, possibly resulting from outliers. In this case, sits_cluster_clean() removes the outliers, leaving only the most frequent label. After cleaning the samples, the resulting set of samples is likely to improve the classification results.
# Remove cluster 3 from the samples
clusters_new <- dplyr::filter(clusters, cluster != 3)
# Clear clusters, leaving only the majority label
clean <- sits_cluster_clean(clusters_new)
# Show clusters samples frequency
sits_cluster_frequency(clean)#>
#> 1 2 4 5 6 Total
#> Cerrado 203 0 80 0 80 363
#> Pasture 0 176 0 140 0 316
#> Total 203 176 80 140 80 679Using SOM for sample quality control
sits provides a clustering technique based on self-organizing maps (SOM) as an alternative to hierarchical clustering for quality control of training samples. SOM is a dimensionality reduction technique [40], where high-dimensional data is mapped into a two-dimensional map, keeping the topological relations between data patterns. As shown in Figure 56, the SOM 2D map is composed of units called neurons. Each neuron has a weight vector, with the same dimension as the training samples. At the start, neurons are assigned a small random value and then trained by competitive learning. The algorithm computes the distances of each member of the training set to all neurons and finds the neuron closest to the input, called the best matching unit.
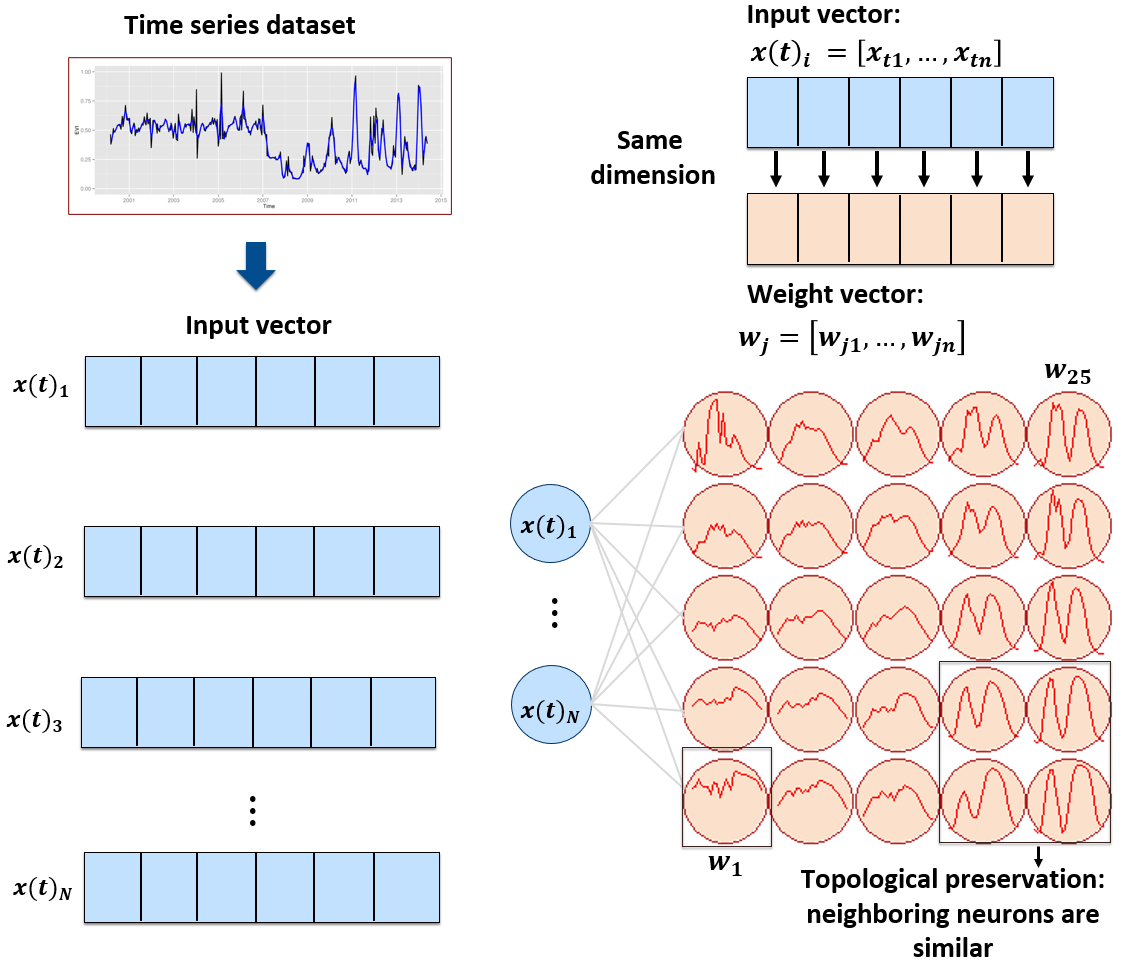
Figure 56: SOM 2D map creation (Source: Santos et al. (2021). Reproduction under fair use doctrine).
The input data for quality assessment is a set of training samples, which are high-dimensional data; for example, a time series with 25 instances of 4 spectral bands has 100 dimensions. When projecting a high-dimensional dataset into a 2D SOM map, the units of the map (called neurons) compete for each sample. Each time series will be mapped to one of the neurons. Since the number of neurons is smaller than the number of classes, each neuron will be associated with many time series. The resulting 2D map will be a set of clusters. Given that SOM preserves the topological structure of neighborhoods in multiple dimensions, clusters that contain training samples with a given label will usually be neighbors in 2D space. The neighbors of each neuron of a SOM map provide information on intraclass and interclass variability, which is used to detect noisy samples. The methodology of using SOM for sample quality assessment is discussed in detail in the reference paper [41].
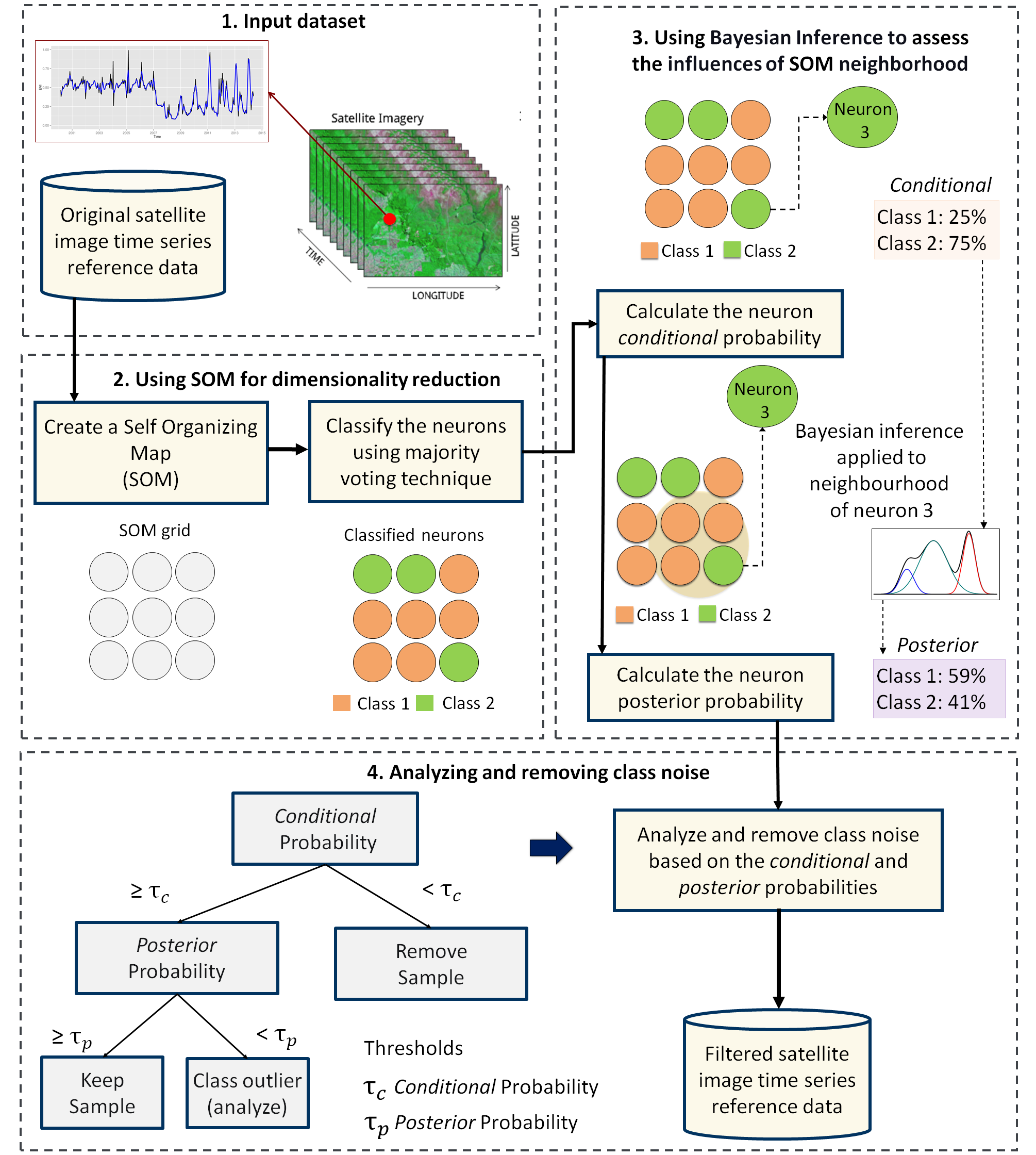
Figure 57: Using SOM for class noise reduction (Source: Santos et al. (2021). Reproduction under fair use doctrine).
Creating the SOM map
To perform the SOM-based quality assessment, the first step is to run sits_som_map(), which uses the kohonen R package to compute a SOM grid [42], controlled by five parameters. The grid size is given by grid_xdim and grid_ydim. The starting learning rate is alpha, which decreases during the interactions. To measure the separation between samples, use distance (either “dtw” or “euclidean”). The number of iterations is set by rlen. When using sits_som_map() in machines which have multiprocessing support for the OpenMP protocol, setting the laerning mode parameter mode to “patch” improves processing time. In MacOS and Windows, please use “online”.
We suggest using the Dynamic Time Warping (“dtw”) metric as the distance measure. It is a technique used to measure the similarity between two temporal sequences that may vary in speed or timing [43]. The core idea of DTW is to find the optimal alignment between two sequences by allowing non-linear mapping of one sequence onto another. In time series analysis, DTW matches two series slightly out of sync. This property is useful in land use studies for matching time series of agricultural areas [44].
# Clustering time series using SOM
som_cluster <- sits_som_map(samples_cerrado_mod13q1_2bands,
grid_xdim = 15,
grid_ydim = 15,
alpha = 1.0,
distance = "dtw",
rlen = 20
)
# Plot the SOM map
plot(som_cluster)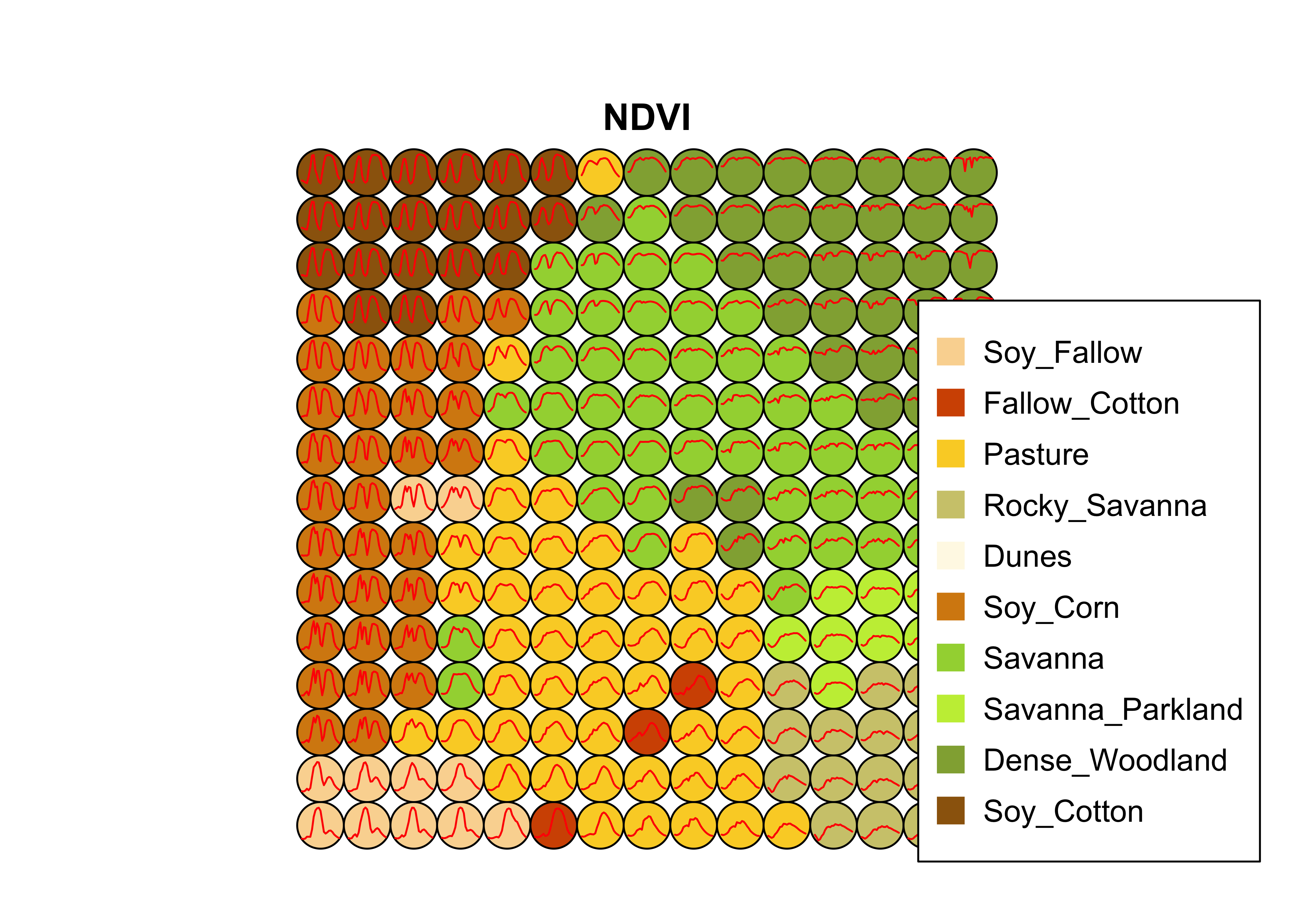
Figure 58: SOM map for the Cerrado samples (source: authors).
The output of the sits_som_map() is a list with three elements: (a) data, the original set of time series with two additional columns for each time series: id_sample (the original id of each sample) and id_neuron (the id of the neuron to which it belongs); (b) labelled_neurons, a tibble with information on the neurons. For each neuron, it gives the prior and posterior probabilities of all labels which occur in the samples assigned to it; and (c) the SOM grid. To plot the SOM grid, use plot(). The neurons are labelled using majority voting.
The SOM grid shows that most classes are associated with neurons close to each other, although there are exceptions. Some Pasture neurons are far from the main cluster because the transition between open savanna and pasture areas is not always well defined and depends on climate and latitude. Also, the neurons associated with Soy_Fallow are dispersed in the map, indicating possible problems in distinguishing this class from the other agricultural classes. The SOM map can be used to remove outliers, as shown below.
Measuring confusion between labels using SOM
The second step in SOM-based quality assessment is understanding the confusion between labels. The function sits_som_evaluate_cluster() groups neurons by their majority label and produces a tibble. Neurons are grouped into clusters, and there will be as many clusters as there are labels. The results shows the percentage of samples of each label in each cluster. Ideally, all samples of each cluster would have the same label. In practice, cluster contain samples with different label. This information helps on measuring the confusion between samples.
# Produce a tibble with a summary of the mixed labels
som_eval <- sits_som_evaluate_cluster(som_cluster)
# Show the result
som_eval#> # A tibble: 66 × 4
#> id_cluster cluster class mixture_percentage
#> <int> <chr> <chr> <dbl>
#> 1 1 Dense_Woodland Dense_Woodland 78.1
#> 2 1 Dense_Woodland Pasture 5.56
#> 3 1 Dense_Woodland Rocky_Savanna 8.95
#> 4 1 Dense_Woodland Savanna 3.88
#> 5 1 Dense_Woodland Silviculture 3.48
#> 6 1 Dense_Woodland Soy_Corn 0.0249
#> 7 2 Dunes Dunes 100
#> 8 3 Fallow_Cotton Dense_Woodland 0.169
#> 9 3 Fallow_Cotton Fallow_Cotton 49.5
#> 10 3 Fallow_Cotton Millet_Cotton 13.9
#> # ℹ 56 more rowsMany labels are associated with clusters where there are some samples with a different label. Such confusion between labels arises because sample labeling is subjective and can be biased. In many cases, interpreters use high-resolution data to identify samples. However, the actual images to be classified are captured by satellites with lower resolution. In our case study, a MOD13Q1 image has pixels with 250 m resolution. As such, the correspondence between labeled locations in high-resolution images and mid to low-resolution images is not direct. The confusion by sample label can be visualized in a bar plot using plot(), as shown below. The bar plot shows some confusion between the labels associated with the natural vegetation typical of the Brazilian Cerrado (Savanna, Savanna_Parkland, Rocky_Savanna). This mixture is due to the large variability of the natural vegetation of the Cerrado biome, which makes it difficult to draw sharp boundaries between classes. Some confusion is also visible between the agricultural classes. The Millet_Cotton class is a particularly difficult one since many of the samples assigned to this class are confused with Soy_Cotton and Fallow_Cotton.
# Plot the confusion between clusters
plot(som_eval)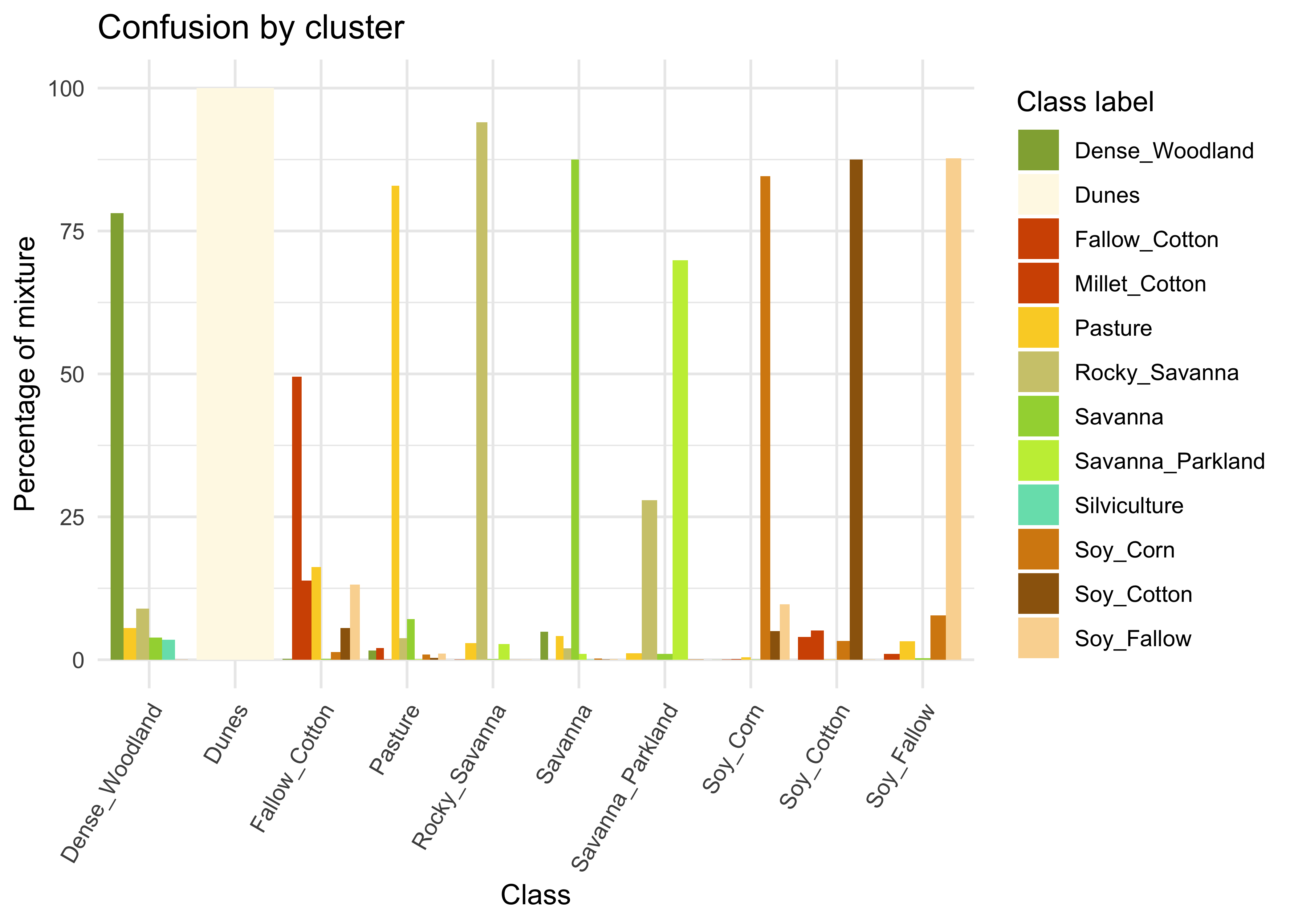
Figure 59: Confusion between classes as measured by SOM (source: authors).
Detecting noisy samples using SOM
The third step in the quality assessment uses the discrete probability distribution associated with each neuron, which is included in the labeled_neurons tibble produced by sits_som_map(). This approach associates probabilities with frequency of occurrence. More homogeneous neurons (those with one label has high frequency) are assumed to be composed of good quality samples. Heterogeneous neurons (those with two or more classes with significant frequencies) are likely to contain noisy samples. The algorithm computes two values for each sample:
prior probability: the probability that the label assigned to the sample is correct, considering the frequency of samples in the same neuron. For example, if a neuron has 20 samples, of which 15 are labeled as
Pastureand 5 asForest, all samples labeled Forest are assigned a prior probability of 25%. This indicates that Forest samples in this neuron may not be of good quality.posterior probability: the probability that the label assigned to the sample is correct, considering the neighboring neurons. Take the case of the above-mentioned neuron whose samples labeled
Pasturehave a prior probability of 75%. What happens if all the neighboring neurons haveForestas a majority label? To answer this question, we use Bayesian inference to estimate if these samples are noisy based on the surrounding neurons [45].
To identify noisy samples, we take the result of the sits_som_map() function as the first argument to the function sits_som_clean_samples(). This function finds out which samples are noisy, which are clean, and which need to be further examined by the user. It requires the prior_threshold and posterior_threshold parameters according to the following rules:
- If the prior probability of a sample is less than
prior_threshold, the sample is assumed to be noisy and tagged as “remove”; - If the prior probability is greater or equal to
prior_thresholdand the posterior probability calculated by Bayesian inference is greater or equal toposterior_threshold, the sample is assumed not to be noisy and thus is tagged as “clean”; - If the prior probability is greater or equal to
prior_thresholdand the posterior probability is less thanposterior_threshold, we have a situation when the sample is part of the majority level of those assigned to its neuron, but its label is not consistent with most of its neighbors. This is an anomalous condition and is tagged as “analyze”. Users are encouraged to inspect such samples to find out whether they are in fact noisy or not.
The default value for both prior_threshold and posterior_threshold is 60%. The sits_som_clean_samples() has an additional parameter (keep), which indicates which samples should be kept in the set based on their prior and posterior probabilities. The default for keep is c("clean", "analyze"). As a result of the cleaning, about 900 samples have been considered to be noisy and thus removed.
new_samples <- sits_som_clean_samples(
som_map = som_cluster,
prior_threshold = 0.6,
posterior_threshold = 0.6,
keep = c("clean", "analyze")
)
# Print the new sample distribution
summary(new_samples)#> # A tibble: 9 × 3
#> label count prop
#> <chr> <int> <dbl>
#> 1 Dense_Woodland 8519 0.220
#> 2 Dunes 550 0.0142
#> 3 Pasture 5509 0.142
#> 4 Rocky_Savanna 5508 0.142
#> 5 Savanna 7651 0.197
#> 6 Savanna_Parkland 1619 0.0418
#> 7 Soy_Corn 4595 0.119
#> 8 Soy_Cotton 3515 0.0907
#> 9 Soy_Fallow 1309 0.0338All samples of the class which had the highest confusion with others(Millet_Cotton) have been removed. Most samples of class Silviculture (planted forests) have also been removed since they have been confused with natural forests and woodlands in the SOM map. Further analysis includes calculating the SOM map and confusion matrix for the new set, as shown in the following example.
# Evaluate the mixture in the SOM clusters of new samples
new_cluster <- sits_som_map(
data = new_samples,
grid_xdim = 15,
grid_ydim = 15,
alpha = 1.0,
rlen = 20,
distance = "dtw"
)
new_cluster_mixture <- sits_som_evaluate_cluster(new_cluster)
# Plot the mixture information.
plot(new_cluster_mixture)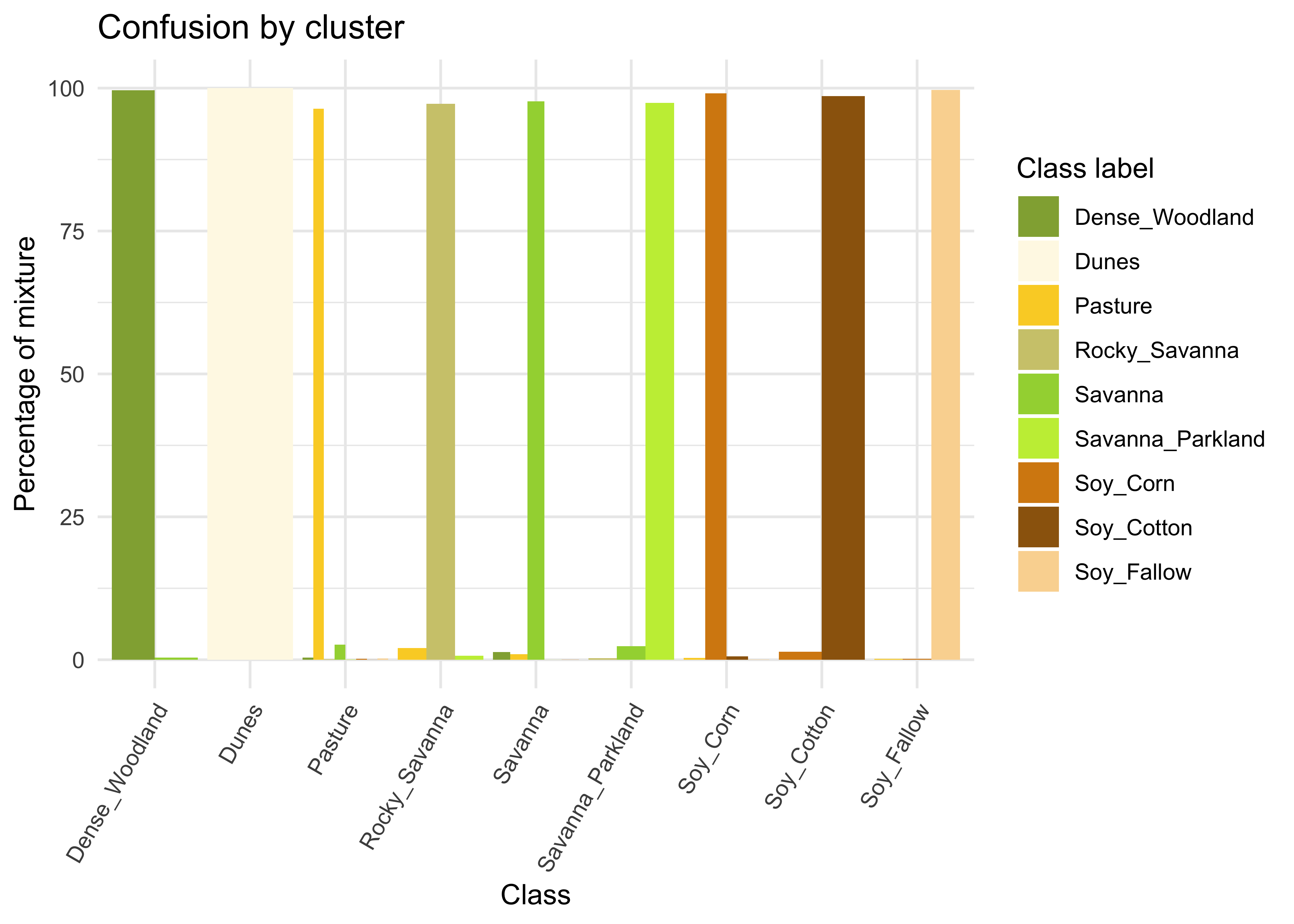
Figure 60: Cluster confusion plot for samples cleaned by SOM (source: authors).
As expected, the new confusion map shows a significant improvement over the previous one. This result should be interpreted carefully since it may be due to different effects. The most direct interpretation is that Millet_Cotton and Silviculture cannot be easily separated from the other classes, given the current attributes (a time series of NDVI and EVI indices from MODIS images). In such situations, users should consider improving the number of samples from the less represented classes, including more MODIS bands, or working with higher resolution satellites. The results of the SOM method should be interpreted based on the users’ understanding of the ecosystems and agricultural practices of the study region.
The SOM-based analysis discards samples that can be confused with samples of other classes. After removing noisy samples or uncertain classes, the dataset obtains a better validation score since there is less confusion between classes. Users should analyse the results with care. Not all discarded samples are low-quality ones. Confusion between samples of different classes can result from inconsistent labeling or from the lack of capacity of satellite data to distinguish between chosen classes. When many samples are discarded, as in the current example, revising the whole classification schema is advisable. The aim of selecting training data should always be to match the reality on the ground to the power of remote sensing data to identify differences. No analysis procedure can replace actual user experience and knowledge of the study region.
Reducing sample imbalance
Many training samples for Earth observation data analysis are imbalanced. This situation arises when the distribution of samples associated with each label is uneven. One example is the Cerrado dataset used in this Chapter. The three most frequent labels (Dense Woodland, Savanna, and Pasture) include 53% of all samples, while the three least frequent labels (Millet-Cotton, Silviculture, and Dunes) comprise only 2.5% of the dataset. Sample imbalance is an undesirable property of a training set since machine learning algorithms tend to be more accurate for classes with many samples. The instances belonging to the minority group are misclassified more often than those belonging to the majority group. Thus, reducing sample imbalance can positively affect classification accuracy [46].
The function sits_reduce_imbalance() deals with training set imbalance; it increases the number of samples of least frequent labels, and reduces the number of samples of most frequent labels. Oversampling requires generating synthetic samples. The package uses the SMOTE method that estimates new samples by considering the cluster formed by the nearest neighbors of each minority label. SMOTE takes two samples from this cluster and produces a new one by randomly interpolating them [47].
To perform undersampling, sits_reduce_imbalance() builds a SOM map for each majority label based on the required number of samples to be selected. Each dimension of the SOM is set to ceiling(sqrt(new_number_samples/4)) to allow a reasonable number of neurons to group similar samples. After calculating the SOM map, the algorithm extracts four samples per neuron to generate a reduced set of samples that approximates the variation of the original one.
The sits_reduce_imbalance() algorithm has two parameters: n_samples_over and n_samples_under. The first parameter indicates the minimum number of samples per class. All classes with samples less than its value are oversampled. The second parameter controls the maximum number of samples per class; all classes with more samples than its value are undersampled. The following example uses sits_reduce_imbalance() with the Cerrado samples. We generate a balanced dataset where all classes have a minimum of 1000 and and a maximum of 1500 samples. We use sits_som_evaluate_cluster() to estimate the confusion between classes of the balanced dataset.
# Reducing imbalances in the Cerrado dataset
balanced_samples <- sits_reduce_imbalance(
samples = samples_cerrado_mod13q1_2bands,
n_samples_over = 1000,
n_samples_under = 1500,
multicores = 4
)
# Print the balanced samples
# Some classes have more than 1500 samples due to the SOM map
# Each label has between 10% and 6% of the full set
summary(balanced_samples)#> # A tibble: 12 × 3
#> label count prop
#> <chr> <int> <dbl>
#> 1 Dense_Woodland 1596 0.0974
#> 2 Dunes 1000 0.0610
#> 3 Fallow_Cotton 1000 0.0610
#> 4 Millet_Cotton 1000 0.0610
#> 5 Pasture 1592 0.0971
#> 6 Rocky_Savanna 1476 0.0901
#> 7 Savanna 1600 0.0976
#> 8 Savanna_Parkland 1564 0.0954
#> 9 Silviculture 1000 0.0610
#> 10 Soy_Corn 1588 0.0969
#> 11 Soy_Cotton 1568 0.0957
#> 12 Soy_Fallow 1404 0.0857
# Clustering time series using SOM
som_cluster_bal <- sits_som_map(
data = balanced_samples,
grid_xdim = 15,
grid_ydim = 15,
alpha = 1.0,
distance = "dtw",
rlen = 20,
mode = "pbatch"
)
# Produce a tibble with a summary of the mixed labels
som_eval <- sits_som_evaluate_cluster(som_cluster_bal)
# Show the result
plot(som_eval)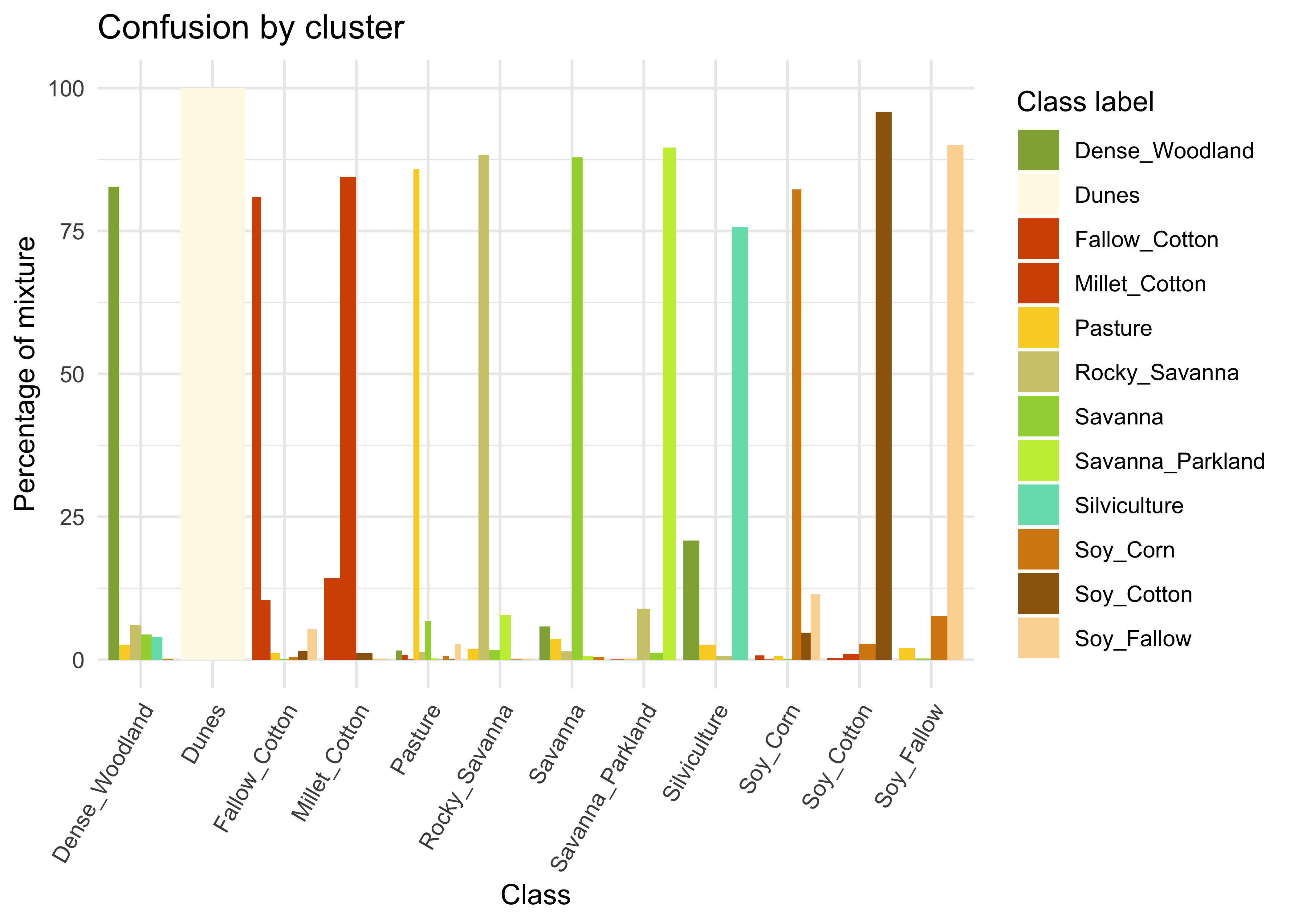
Figure 61: Confusion by cluster for the balanced dataset (source: authors).
As shown in Figure 61, the balanced dataset shows less confusion per label than the unbalanced one. In this case, many classes that were confused with others in the original confusion map are now better represented. Reducing sample imbalance should be tried as an alternative to reducing the number of samples of the classes using SOM. In general, users should balance their training data for better performance.
Conclusion
The quality of training data is critical to improving the accuracy of maps resulting from machine learning classification methods. To address this challenge, the sits package provides three methods for improving training samples. For large datasets, we recommend using both imbalance-reducing and SOM-based algorithms. The SOM-based method identifies potential mislabeled samples and outliers that require further investigation. The results demonstrate a positive impact on the overall classification accuracy.
The complexity and diversity of our planet defy simple label names with hard boundaries. Due to representational and data handling issues, all classification systems have a limited number of categories, which inevitably fail to adequately describe the nuances of the planet’s landscapes. All representation systems are thus limited and application-dependent. As stated by Janowicz [48]: “geographical concepts are situated and context-dependent and can be described from different, equally valid, points of view; thus, ontological commitments are arbitrary to a large extent”.
The availability of big data and satellite image time series is a further challenge. In principle, image time series can capture more subtle changes for land classification. Experts must conceive classification systems and training data collections by understanding how time series information relates to actual land change. Methods for quality analysis, such as those presented in this Chapter, cannot replace user understanding and informed choices.