32 How parallel processing works in SITS
This section provides an overview of how sits_classify(), sits_smooth(), and sits_label_classification() process images in parallel. To achieve efficiency, sits implements a fault-tolerant multitasking procedure for big Earth observation data classification. The learning curve is shortened as there is no need to learn how to do multiprocessing. Image classification in sits is done by a cluster of independent workers linked to a virtual machine. To avoid communication overhead, all large payloads are read and stored independently; direct interaction between the main process and the workers is kept at a minimum.
The classification procedure benefits from the fact that most images available in cloud collections are stored as COGs (cloud-optimized GeoTIFF). COGs are regular GeoTIFF files organized in regular square blocks to improve visualization and access for large datasets. Thus, data requests can be optimized to access only portions of the images. All cloud services supported by sits use COG files. The classification algorithm in sits uses COGs to ensure optimal data access, reducing I/O demand as much as possible.
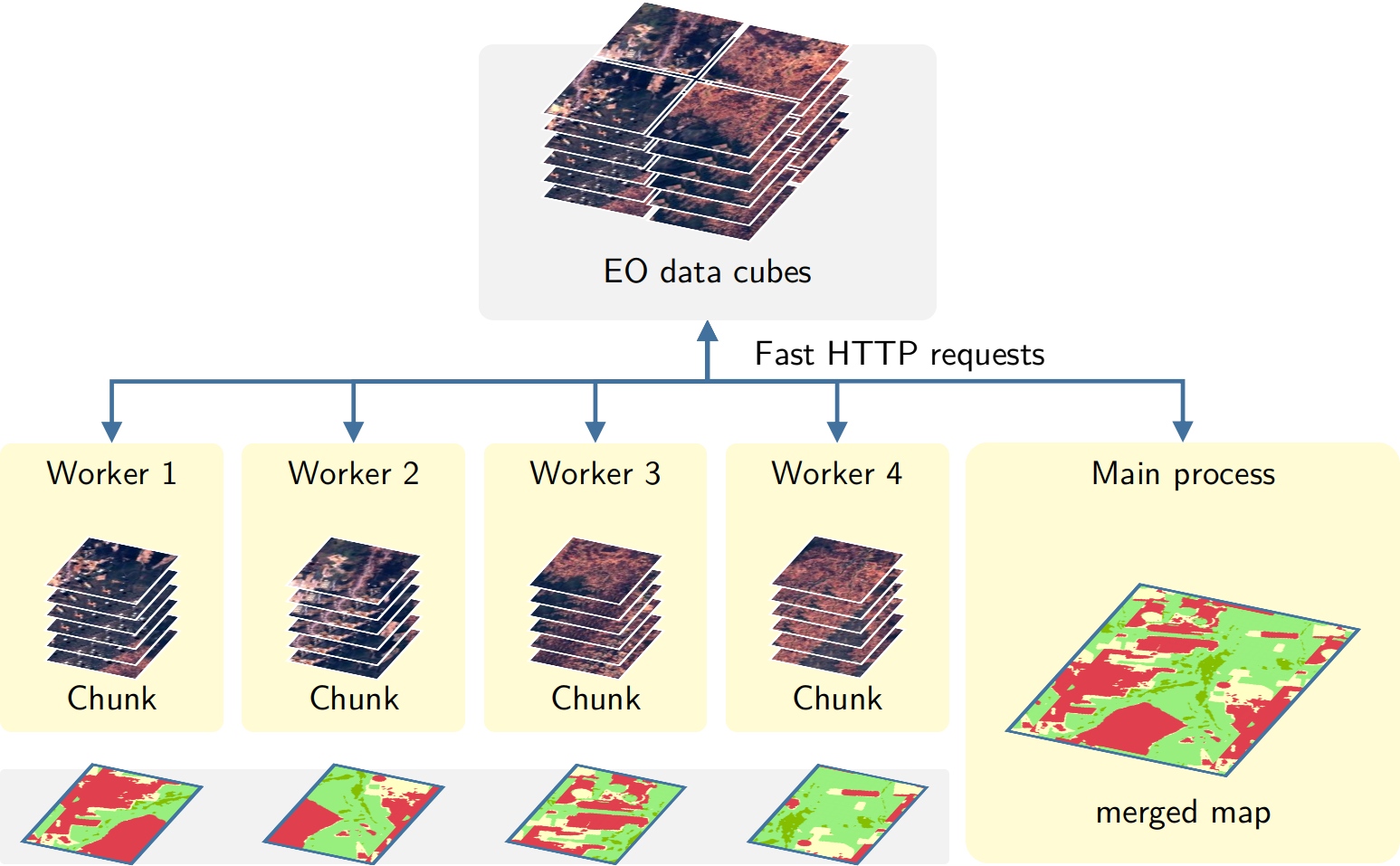
The approach for parallel processing in sits, depicted in Figure 32.1, has the following steps:
- Based on the block size of individual COG files, calculate the size of each chunk that must be loaded in memory, considering the number of bands and the timeline’s length. Chunk access is optimized for the efficient transfer of data blocks.
- Divide the total memory available by the chunk size to determine how many processes can run in parallel.
- Each core processes a chunk and produces a subset of the result.
- Repeat the process until all chunks in the cube have been processed.
- Check that subimages have been produced correctly. If there is a problem with one or more subimages, run a failure recovery procedure to ensure all data is processed.
- After generating all subimages, join them to obtain the result.
This approach has many advantages. It has no dependencies on proprietary software and runs in any virtual machine that supports R. Processing is done in a concurrent and independent way, with no communication between workers. Failure of one worker does not cause the failure of big data processing. The software is prepared to resume classification processing from the last processed chunk, preventing failures such as memory exhaustion, power supply interruption, or network breakdown.
To reduce processing time, it is necessary to adjust sits_classify(), sits_smooth(), and sits_label_classification() according to the capabilities of the host environment. The memsize parameter controls the size of the main memory (in GBytes) to be used for classification. A practical approach is to set memsize to the maximum memory available in the virtual machine for classification and to choose multicores as the largest number of cores available. Based on the memory available and the size of blocks in COG files, sits will access the images in an optimized way. In this way, sits tries to ensure the best possible use of the available resources.